
몇 가지의 운영체제, 서버의 자원, 네트워크, 데이터 베이스 등 필요한 지식에 대해 알아보자.
성능 테스트는 어떤 상황에서 왜 하는가?
서버의 숫자
서비스를 개발하고 서버에 배포한 후 많은 서비스를 운영하면서 많은 사용자가 동시에 접속하면 서버 자원을 많이 사용하게 된다. 서버 자원은 무한하지 않기 때문에 많은 사용자를 처리하려면 여러 대의 서버가 필요하다. 하지만, 서버를 무한정 늘릴 수는 없으므로(비용) 적절한 서버 수를 결정하는 것이 중요하다.
사용자가 발생시키는 트래픽을 감당하기 위해서는 얼마나 많은 서버가 있어야 할까?
이를 위해 성능 테스트 도구를 사용해 사용자가 많아졌을 때를 시뮬레이션할 수 있다. 성능 테스트 툴은 사용자의 요청을 생성하여 서버의 성능을 테스트하고, 그 결과를 리포트해 준다.
성능 테스트 결과를 반혹하여 예상되는 사용자 숫자와 그에 따른 요청 수를 계산하여 얼마나 많은 수의 서버가 필요한지 테스트 해볼 수 있다.
비효율적인 로직
메모리 정리가 제대로 되지 않아 지속적으로 GC가 발생하는 문제를 예시로 들 수 있다.
많은 요청을 해보지 않는다면 이런 비효율적인 로직을 찾아내는 것은 어려운데 막상 트래픽이 많이 들어올 때 이런 부분에서 문제가 발생할 수 있다.
데이터베이스 - 인덱스, 데드락
데이터 베이스도 애플리케이션이 사용하는 물리적인 존재기 때문에 많은 데이터가 저장되고 많은 조회 요청이 들어오면 느려질 가능성이 훨씬 높다.
이럴 때 조회 요청이 인덱스를 타지 않거나 데드락이 발생할 수 있다.
시스템 설계 개선
많은 트래픽을 처리하기 위해서 시스템이 구조적으로 바뀌어야하는 상황도 있다.
- 캐시 필요
- 비동기처리
- 서킷 브레이커
트래픽: 많은 데이터가 흐르면 트래픽이 많다/ 적은 데이터가 흐르면 트래픽이 적다고 말할 수 있다.
- 절대적인 기준이 있는 것은 아니다.
- 통상적으로 웹 브라우저를 혼자서 새로고침 하며 발생시키는 트래픽은 낮다고 볼 수 있다.
- 성능테스트 툴로 트래픽을 발생시키면 많은 트래픽을 만들어 낼 수 있다.
- 이러한 이유로 성능테스트를 통해 실제 사용자들이 사용하는 상황과 유사한 환경을 만들고 미리 동일한 트래픽을 받아 볼 수 있다.
지연 시간(Latency)와 처리량(Throughput)
지연 시간(Latency)
요청 한건 한건의 처리시간을 의미
주로 ms 단위
어떤 요청이 처리되어 사용자에게 응답이 되기까지 1초가 걸렸다면 해당 요청의 지연시간은 1초다.
사용자가 체감하는 중요한 성능 지표다.
처리량(Throughput)
단위 시간 동안 몇건의 요청을 처리할 수 있는가?
주로 tps(transaction per second) 단위
어떤 API가 1초 동안 1,000개의 API 요청이 들어올 때 1,000개의 요청을 문제없이 처리해낼 수 있다고 하면 이 API의 tps는 1,000tps 이상이라고 볼 수 있다.
트랜잭션: 웹 어플리케이션에서는 HTTP 요청에 대한 응답 하나의 묶음을 의미 (한건의 요청)
비슷한 개념으로 대역폭이라는 단어도 있다.
대역폭: 네트워크가 단위시간 동안 전송할 수 있는 최대한의 처리량
(네트워크를 최대한으로 활용했을 대 얼마나 빠른 속도로 데이터를 보낼 수 있는지를 의미)
- 네트워크에서 유의미한 개념
반면 여기서 말하는 처리량은 측정한 데이터의 전송량이다. 처리량을 계속 올리면서 테스트하다 보면 결국 대역폭에 가까워 진다고 볼 수 있다. (여기서 말할 요소는 대역폭과는 다르다. 백엔드 애플리케이션은 여러 요소들이 간섭을 주기 때문에 정확한 대역폭을 측정하기는 어렵다. 처리량과 지연시간만 집중하자)
지연시간과 처리량 사이의 관계
처리량 증가 ➡️ 서버 자원 사용량 증가 ➡️ 프로세스, 스레드간 자원 사용 대기시간 길어짐 ➡️ 지연시간 길어짐 ➡️ 처리되지 못한 요청 쌓임 ➡️ 요청 중 일부 실패
위와 같이 볼 수 있는데 대기시간이 길어질 때 경쟁상태에 있다면 처리량이 많이 낮아질 수 있다.
(이런 경쟁상태를 해소하기 위한 방법 중 하나가 서킷 브레이커 패턴이 있다.)
성능 테스트에서의 지연시간과 처리량
주로 처리량과 지연시간을 결합해서 성능 테스트 목표를 세운다.
초당 요청이 몇 건으로 들어올 때, 몇%의 요청의 지연시간이 몇ms 미만으로 처리되어야 한다.
100%가 아닌 이유는 성능 테스트에는 많은 변수가 있기 때문에 100%는 힘들어서 보통 99%나 95% 정도로 목표 삼는다
목표를 맞추기 위해 성능 테스트를 진행해야한다.
처리량과 지연시간 동시에 목표해야하는 이유
일반적으로 처리량이 낮을 때는 지연시간이 낮고 일정하게 유지되다가
처리량이 점점 높아지면 지연시간이 함께 높아지는 경향이 있다.
처리량이 많아지면 서버가 바빠져서 자원이 부족해지면 요청을 처리하기 위해 자원을 쓸 수 있을 때까지 대기하는 시간이 필요해진다.
운영체제
운영체제: 컴퓨터의 물리적인 자원을 관리하면서 필요한 곳에 자원을 할당하여 컴퓨터에서 애플리케이션을 실행하도록 도와주는 역할을 하는 것
ex) windows, macOS, Linux
서버에서 주로 사용되는 운영체제는 리눅스다. 서버는 크게 물리적으로 CPU, 메모리 디스크 같은 자원을 가지고 있다.
서버에 백엔드 애플리케이션을 배포해서 실행시키면 운영체제는 백엔드 애플리케이션을 프로세스라로 생성해서 관리한다. 프로세스는 필요한 자원(CPU, 메모리, 디스크 등)을 할당받아 작업을 처리한다.
어떤 작업은 CPU가 많이 필요할 수도 있고 메모리나 디스크를 많이 사용할 수도 있는데 이러한 자원도 유한하다. 때문에 어떠한 자원이 부족하면 요청이 지연될 수도 있다.
이런점은 성능 테스트를 할 때 서버가 가지고 있는 자원 중 사용률이 높아지는 자원이 있다면 해당 자원의 사용률을 낮추는 방안을 고민할 필요가 있다.
프로그램: 디스크에 저장되어 있는 실행할 수 있는 파일이나 소프트웨어 집합
ex) Java 애플리케이션의 jar 파일
이러한 프로그램이 메모리에 올라와서 실행이 되면 프로세스라 불린다.
프로세스: 작업의 실행 단위, 현재 실행 중인 프로그램
프로세스를 간단히 나누면 메모리와 코드로 이루어져 있다.
CPU는 프로세스가 가진 코드에 따라 프로세스를 실행시키는데 메모리가 코드에 따라 수동적으로 사용되어 CPU와 메모리가 서로 상호작용을 한다.
그리고 프로세스의 숫자가 많아져서 램(보통 32GB 아래)위에 모든 프로세스를 올릴 수 없어지면 페이징을 하여 가상메모리(디스크)를 사용하게 되는데 이때 메모리와 디스크가 상호작용한다.
일단, 프로세스를 사용하려면 CPU, 메모리, 디스크가 필요하다는 것을 생각하자.
CPU
CPU는 주로
- 사측 연산이나 수학적인 연산이 필요한 메소드를 호출하는 계산 작업
- 이미지나 영상 인코딩
- 암호화 or 해시화
같은 작업에서 많이 사용된다.
메모리(RAM)
CPU와 상호작용하는 일이 많기 때문에 CPU와 함께 많이 쓰는 경우도 많고,
인스턴스를 대량으로 계속 생성하는 경우같은 메모리만 많이 사용하게 되는 경우도 있다.
사용하지 않는 인스턴스를 많이 만들 경우 CPU 가 개입해서 정리할 수도 있는데 이럴경우 메모리 사용량이 높아졌다가 떨어질 수 있는데 이때 CPU 사용률이 올라간다고 볼 수 있다.
반면 캐싱이나 컬렉션 같은 경우엔 CPU 사용량은 크지 않고 메모리 사용량이 높을 수 있다.
메모리의 경우 공간을 얼마나 사용하느냐도 중요하지만 메모리로 데이터가 빠르게 들어오고 나가는 속도도 중요하다.
디스크
파일 입출력이 발생할 때 많이 사용된다.
예를들면 로그를 파일에 기록할 때 파일 입출력이 실행되면서 사용될 수 있다.
또한 데이터베이스를 삽입하거나 조회할 때 데이터베이스를 가지고 있는 디스크를 사용할 수도 있다.
디스크도 메모리와 마찬가지로 공간 차지량 보다 얼마나 많은 양의 데이터가 읽혀지고 쓰여지고 있는지 속도 자체가 중요하다.
네트워크
성능 테스트에서의 네트워크는 중요한 요소다.
API 서버가 요청에 대한 응답을 주려면 요청을 처리하는 과정이 필요한데 해당 과정은 다양하다.
백엔드 애플리케이션이 자신의 서버(내부자원) 뿐 아니라 데이터베이스를 조회하거나 다른 API 서버를 호출하거나 할 때 다른 서버의 자원을 사용할 수도 있다. 다른 서버에 있는 자원을 사용하려면 네트워크 통신(IO)이 필요하다.
네트워크 통신은 비용이 큰 작업이다.
서버 내부 자원을 사용하는 연산은 보통 1ms가 걸리지 않고 네트워크 통신은 보통 1ms 가 넘는다.
때문에 지연시간을 줄이기 위해선 네트워크 통신 성능 개선도 고려하는 것이 좋다.(캐시활용, DB 개선)
웹브라우저 개발자 도구의 네트워크 탭에서 지연시간 확인할 수 있다.
네트워크는 물리적인 거리의 제약을 받는다.
네트워크의 속도는 빛의 속도보다 빠르지 않다. 빛의 속도가 1초에 7.5바퀴를 돌면 한 바퀴 도는 데 133.3ms가 걸린다. 지구 반대편의 서버 자원을 사용하려고 했을 때 요청을 보냈다가 받아야 하니까 1바퀴를 돈다고 생각하면 133.3ms 보다는 클 것이라고 생각할 수 있다.(직선도 아니고 중간에 여러 추가 처리과정(라우터 등)도 거친다)
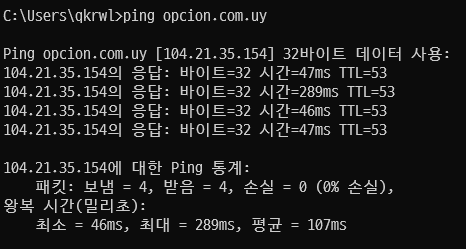

인프런 서버가 우루과이 서버보다 지연시간이 더 빠른것을 확인할 수 있다.
실무에서는 IDC라는 단위로 서버들이 모여 있는데 같은 IDC 내에서 서버들 끼리는 1ms 미만의 시간으로도 통신할 수 있다고 한다.
참고: 다른 몇 곳도 테스트 해봤는데 보안상의 이유로 막아놓은 듯 하다.
네트워크 대역폭과 지연시간의 관계
만약 대역폭이 초당 100Mbps를 보낼 수 있는 선로가 있다고 가정했을 때, 클라이언트가 이 100Mbps를 전부 다 사용하고 있다고 생각하자. 여기서 다른 클라이언트가 동일한 회선으로 50Mbps를 추가로 보낸다면 100Mbps 회선에서 150Mbps 데이터 전송을 시도하면 50MBps의 데이터는 보내지 못하고 네트워크 장비나 각각의 클라이언트에게 쌓일 것이다. 결국 해당 요청은 지연시간이 늘어날 것이다.
예시
- 대용량의 파일을 다운로드 하고 있을 때 웹서핑이 느림
- 고해상도 이미지가 많이 포함된 페이지에 접속했을 때 이미지가 느림(이미지 제공 서버의 대역폭 문제일 수 있다.)
위와 같은 상황에서는 회선의 대역폭을 많이 사용하고 있어 지연될 수 있다.
또한 네트워크에서 대역폰은 경로상에 있는 가장 낮은 대역폭을 가지는 선로에 맞춰진다.
데이터베이스
데이터베이스도 하나의 어플리케이션으로서, 실행되는 프로세스다.
즉, CPU, 메모리, 디스크를 사용해 저장이나 조회를 하는 것이다.
| CPU | 사용자가 원하는 데이터인지 확인하는 연산을 한다. |
| 메모리 | 필요한 데이터를 메모리에 올려 CPU가 연산할 수 있게 준비 혹은 빠르게 처리하기 위해 캐시 |
| 디스크 | 데이터들이 저장되어 있다. |
데이터베이스의 지연시간과 처리량
데이터베이스의 지연시간이 길어지는 상황들
- 짧은 시간 동안 많은 요청이 들어오는 경우
- = 처리량이 커지면 지연시간이 길어질 수 있다.
- 물리적인 자원들을 활용해서 요청을 처리하기 때문에 자원들이 경쟁상태에 빠질 수 있기 때문이다.
- 많은 데이터가 저장되어 있는 경우
- 1억건의 데이터에서 필요한 데이터를 찾으려면 1억건이 디스크에 저장되어 있고, 이부를 메모리에 올리고 CPU가 연산을 하게된다.
- 이런 문제를 해결하기 위해 검색 조건이 되는 데이터를 기준으로 인덱스를 걸곤 한다.
- 응답 자체의 데이터 사이즈가 큰 경우
- 응답 데이터 사이즈가 크다면 데이터베이스 서버 자원 자체도 데이터를 메모리에 올리기 위해 많은 비용이 든다.
- 서버 자원도 많이 사용하기 때문에 다른 요청들의 성능에도 영향을 함께 준다.
- 데이터베이스가 트랜잭션을 지원하기 위해 걸리는 락이 너무 자주 걸리는 경우
- 락을 좁은 범위의 데이터에 적용하고 더 짧은 시간 동안만 걸리게 하도록 고려해야 한다.
락은 동시성 문제에서 많이 나오는 개념이다.
특정 스레드가 데이터를 제어하고 있으면 다른 스레드의 접근을 막는다.
데이터베이스는 기본적으로 락을 걸어 트랜잭셔널한 처리를 지원한다.
때로는 락에 의해서 데드락이 발생하는데 데드락은 쓰레드가 기다리게 되고 요청들이 점점 쌓여서 서버의 모든 자원을 고갈시켜 버리기도 한다.
이런 락은 성능에 좋지 않다.
- 디스크 속도 HDD와 SSD
- 데이터베이스는 많은 데이터를 가지고 있기 때문에 디스크 속도도 중요하다 .
- 디스크는 CPU나 메모리에 비해 훨씬 느리다.
- 데이터에 저장된 디스크 속도가 느리면 메모리와 CPU도 느린 디스크에 맞게 동작한다.
- 성능이 중요한 데이터베이스라면 SSD를 도입하는 것이 좋다.
HDD와 SSD는 디스크 종류다
SSD가 HDD보다 용량은 좀 더 작고 비싸지만 속도가 훨씬 빠르다.
비용문제 때문에 최근 내용은 SSD 잘 사용안되는 데이터는 HDD에 저장하는 식으로 혼합해서 사용하기도 한다.
- 서로 다른 IDC로 데이터베이스 이중화 구성
- 데이터 베이스 이중화를 위해선 두 IDC 사이 갱신되는 데이터를 주고 받아야한다.(동기화작업)
- 여기서 주고받는 데이터는 크다. 때문에 두IDC간의 연결 네트워크 회선의 대역폭도 많이 쓸 것이다.
- 그럼 해당 네트워크 회선을 사용하는 다른 요청(서버들이 사용하는 요청)의 지연시간이 길어진다.
- 전체 서비스의 성능에 악영향을 줄 수 있다.
- 이런 문제를 막기위해 데이터 베이스를 서로 다른 IDC를 위치 시킬 때 둘만 사용하는 전용회선을 별도로 구성하기도 한다.
- 이러면 다른 서버들이 주고받는 데이터의 대역폭에는 영향을 주지 않는다.
- 데이터 베이스 이중화를 위해선 두 IDC 사이 갱신되는 데이터를 주고 받아야한다.(동기화작업)
Thread Pool과 Connection Pool
- Thread Pool: 애플리케이션 서버가 요청을 받아 처리하는 자원
(자바에서 톰켓 서버를 사용하면 기본적으로 200개의 쓰레드가 생성되어 요청을 처리한다.
이 쓰레드들은 미리 생성되어 요청이 오면 요청을 처리하고 처리한 후에는 반납한다.)
- Pool: 자원을 미리 만들어두고 재사용하는 개념
둘은 기본적으로 생성되는 숫자가 정해져 있어서 성능 테스트를 진행하며 튜닝 해주어야할 일이 많고 성능테스트를 할 때 가장먼저 나타나는 문제 요소이기도 하다.
Thread
데드락이 발생하면 대기 중인 상태가 되어 실질적인 서버 물리자원은 많이 소모하진 않지만, 스레드 풀이나 커넥션 풀처럼 제한적인 숫자만 생성되는 자원이 빠르게 소모된다.
요청의 지연시간이 길어지면 트래픽이 늘어나고 모든 쓰레드가 사용중인 상태가 된다면 큐에 요청이 저장될 것이고 해당 큐도 차게 된다면 요청들은 버려지게 된다.
그럼 Thread 수를 무작정 늘리면 될까?
아니다. 쓰레드 수가 많다면 동시에 많은 요청을 처리할 것이고 이러면 서버의 물리적 자원이 고갈되어 경쟁 상태가 될 것이다. 이러면 적은 숫자의 쓰레드로 요청하는 것보다 처리량이 낮아질 수도 있다.
이런 문제는 로드밸런싱을 하여 여러 서버가 트래픽을 받도록 개선하거나
고정된 쓰레드 수를 정해두고 요청을 처리하는 것이 아닌 비동기적으로 요청을 처리하는 것이 좋다.
단순 서버 수를 늘리거나 비동기를 도입한다고해서 성능이 개선되지 않을 수 있다.
백엔드 애플리케이션이 요청을 처리하는 과정에서 다른 인프라 요소에 의존하고 있다면 인프라 요소에 많은 부하가 가해져서 느려지고 성능이 인프아 요소에 맞춰질 수 있게 된다.
근본적으로 해결하려면 병목이 되는 부분을 개설하거나 설계 자체를 바꿔야 할 수도 있다.
Connection
Connection도 Thread와 비슷하게 최대 커넥션 수 제한이 있다. 애플리케이션이 많다면 커넥션 풀이 생성이 되지 않을 것이다.
커넥션 수가 제한된 이유?
커넥션이 너무 많으면 데이터 베이스 서버의 자원에 대한 경쟁 상태가 될 수 있다.
여러 번 성능 테스트를 해서 적절한 수를 찾아야한다.
성능 테스트의 방향성
실무 환경 과 아닌 환경에서의 차이
성능 테스트를 할 때 실무 환경과 아닌 환경에서 진행하는 성능 테스트는 차이가 있다.
인프라 비용
실무에서는 많은 처리량을 감당할 수 있는 충분한 인프라를 투입할 수 있지만
아니라면 인프라를 제대로 구성해서 테스트 하기 어렵다.
테스트 목표
실무에서는 회사의 자원을 사용하여 인프라를 갖추고 성능 테스트와 튜닝을 진행하여 예상 동시 사용자 수와 요청 TPS, 지연시간 등의 목표가 있을 수 있다.
실무가 아니라면 목표가 존재하지 않는다. 하기 나름이고 인프라 자원을 투입하기도 어렵다.
실무가 아닌 환경에서의 성능 테스트
- 한건씩 요청을 보내 지연시간을 확인한다.
- 처리량을 점점 높이면서 지연시간이 치솟는 지점이 언제인지 테스트 해본다.(인프라 구성은 그대로 유지한채로 진행)
- 지점이 식별되면 그 지점부터 성능을 개선 시작한다.
- 테스트를 반복하면서 어떤 부분이 병목이 되고 있는지 가설을 세운다.
- 확인은 서버의 자원을 모니터링하거나 로그 등을 통해 해당 기능이 수행되는데 어느 정도의 시간이 걸리는지 확인하며 병목 지점을 탐
- 병목되는 지점을 식별했다면 병목을 해결할 수 있는 방법들을 적용한다.
- 예시
- 로직 바꾸기
- 인덱스 추가하기
- 설계 바꾸기
- 예시
정리
정리 포인트!
[성능 테스트가 필요한 이유]
- 서버는 비용이 들기때문에 적절한 서버 수를 결정하는 것이 중요하다.
- 비효율적인 로직이 있을 수 있다.
- 데이터 베이스의 문제가 있을 수 있다.
[운영체제]
- CPU, 메모리, 디스크가 서로 상호작용한다.
- 특정 자원의 사용량이 높으면 해당 자원의 사용량을 낮추기 위한 고민이 필요하다.
- 경쟁상태가 되면 처리량이 낮아질 수 있다.
[네트워크]
- 내부 서버 자원이 아닌 다른 서버 자원을 사용할 때 네트워크 통신이 필요하다.
- 네트워크 통신은 비용이 큰 작업이다.
- 네트워크는 물리적 거리에 영향을 받는다.
[데이터베이스]
- 데이터베이스도 서버 자원을 사용하는 하나의 애플리케이션이다.
[Thread Pool과 Connection Pool]
- Pool은 자원을 만들어두고 재사용하는 개념인데 요청이 많아지면 Thread가 고갈될 수 있고, 백엔드 애플리케이션을 여러개 띄우면 Connection의 최대 개수가 차면 정상적으로 생성되지 않을 수 있다.
- 테스트를 하고 적절한 수를 찾아야 한다.
[방향성]
- 실무가 아닌 환경에서는 비용문제 때문에 인프라를 제대로 구축할 수 없고 목표도 없다.
- 요청을 늘려가며 병목 지점을 찾고 병목을 해결하려고 노력해 볼 수 있다.
'knowledge > computer science' 카테고리의 다른 글
| [성능 테스트] Artillery 시나리오, 파라미터 (0) | 2024.06.07 |
|---|---|
| [성능 테스트] Artillery 설치 (0) | 2024.06.06 |
| 동기식/비동기식 개념과 장단점 (0) | 2024.03.12 |
| 임베디드 시스템, 범용 컴퓨팅 시스템 (0) | 2024.02.26 |
| 프록시 서버: 포워드 프록시와 리버스 프록시 (0) | 2024.02.14 |