
지난글: 트랜잭션 개념과 ACID
Schedule
아래의 두가지 트랜잭션이 있다고 생각해보자.
- K가 H에게 이체를 하는 트랜잭션 1
- H가 본인의 계좌에 입금하는 트랜잭션 2
두 트랜잭션이 있을 때 여러 형태의 실행이 가능할 수 있다.
먼저 각 트랜잭션의 operation 순서를 정의하면 아래와 같다.
트랜잭션 1
read(K_balance) -> r1(K)
write(K_balance) -> w1(K)
read(H_balance) -> r1(H)
write(H_balance) -> w1(H)
commit -> c1
트랜잭션 2
read(H_balance) -> r2(H)
write(H_balance) -> w2(H)
commit -> c2
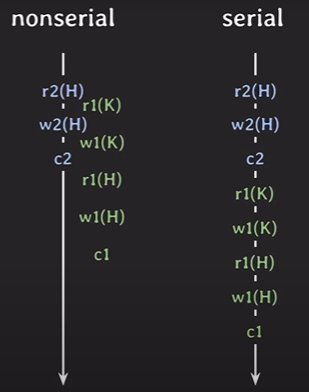
두 트랜잭션이 동시에 실행하면 어떤식으로 실행될지에 대한 케이스 4개를 간소화해서 정리하면 아래와 같다.

📌 schedule
여러 transaction들이 동시에 실행될 때 각 transaction에 속한 operation들의 실행 순서를 schedule이라고 부른다.
- 각 transaction 내의 operations들의 순서는 바뀌지 않는다.
4가지 케이스들이 각각 schedule이라고 볼 수 있는 것이다.
serial schedule
case 1,2 같은 순차적인 스케쥴을 말한다.
한 번에 하나의 트랜잭션만 실행하므로 결과가 이상한 가능성은 없으니 성능은 떨어진다
nonserial schedule
case 3, 4와 같이 transaction들이 겹쳐서(interleabing) 실행되는 스케쥴을 말한다.
I/O작업을 할 때 CPU가 다른 트랜잭션의 작업을 할 수 있으므로 동시성이 높아져 성능은 개선되지만 결과가 이상이 있을 가능성이 높아진다.
고민하기
성능 때문에 여러 transaction들을 겹쳐서 실행할 수 있으면 좋겠지만 이상한 결과가 나오지 않게 하고 싶다.
이를 위해 생각한 것은
serial schedule과 동일한(equivalent) nonserial schedule을 실행하도록 하자.
이다
'schedule이 동일하다' 정의하기
두 operations에 대한 conflict
✅ 세 가지 조건을 모두 만족하면 conflict
1. 서로 다른 transaction 소속
2. 같은 데이터에 접근
3. 최소 하나는 write operation
read-write conflict
3번째 schedule
r1(K) w1(K) r2(H) w2(H) c2 r1(H) w1(H) c1
을 보면 1과 2는 다른 트랜잭션 소속이고,
서로 같은 데이터 H에 접근하고
최소하나는 wrtie operation이다.
conflict에서 하나는 읽고 하나는 쓰는 conflict가 read-write conflitct 라고 한다.(r2(H)와 w1(H), w1(H)와 r2(H))
conflict에서 둘다 쓰는 conflict는 write-write conflict다.(w2(H), w1(H))
이렇게 3번째 schedule에서는 3개의 conflict가 있다고 말할 수 있다.
conflict operation이 순서가 바뀌면 결과도 바뀐다.
w2(H) 의 순서를 바꾸면 r1(H) r1(H)의 결과가 바뀔 것이다.
r1(H)가 앞에있으면 w2(H) 실행되기 이전의 값을, 뒤에있으면 w2(H)가 실행된 후의 값을 읽을 것이기 때문이다.
conflict equivalent
그럼 결국 schedule이 동일하다는 뜻이 무엇일까?
conflict 개념을 사용해서 schedule이 동일하다는 의미를 알아보자.
📌 conflict equivalent
두개의 스케줄이 아래 두 조건을 모두 만족하면 conflict equivalent 라고 할 수 있다.
1. 두 schedule은 같은 transaction들을 가진다.
2. 어떤 conflicting perations 의 순서도 양쪽 schedule 모두 동일하다.
위의 두 조건을 스케줄 2,3 을 통해서 살펴보자.

먼저 첫 번째 조건은
두 스케줄 모두 1과 2의 트랜잭션을 가진다.
때문에 첫 번째 조건을 만족한다고 볼 수 있다.
두 번째 조건을 살펴보면
conflict에서 read-write conflitct (r2(H)와 w1(H), w2(H)와 r1(H)) 2개
write-write conflict (w2(H), w1(H)) 1개
이렇게 3번째 schedule에서는 3개의 conflict가 있다고 하였다.
conflict를 하나씩 살펴보면 3개 모두 순서가 동일하다.
때문에 두 번째 조건도 만족해서 두 조건 모두 만족한다고 볼 수 있는 것이다.
때문에 3번 스케줄을 serail schedule인 2번 스케줄과 conflict equivalent 하다고 볼 수 있다.
📌 Conflict serializable
serial schedule과 conflict equivalent인 스케줄을 Conflict serializable 라고 한다.
conflict serializable은 정상적인 결과를 낼 수 있다.
반면 schedule 4번은 r1(H) w2(H)의 순서를 schedule2번과 비교를 하면 순서가 바뀌어 있음을 알 수 있다.
또한 schedule 1번도 schedule 4번과 비교를 하면 r2(H)와 w1(H)는 순서가 다르다.
결국 schedule 4번은 그 어떤 serial schedule과도 conflict equivalant 하지 않다고 볼 수 있으므로 conflict serializable로 볼 수 없다.
conflict serializable한 nonserial schedule을 사용하면 좋겠지만 실제 트랜잭션은 너무 많기 때문에 비용이 많이 든다.
때문에 보통은 여러 transaction을 동시에 실행해도 schedule이 conflict serializable 하도록 보장하는 프로토콜을 적용하는 방식으로 구현을 한다.
어떤 스케줄이 어떤 serial schedule과 동일하다면 그 스케줄은 serializable하다고 할 수 있다.
동일한 개념은 conflict equivalent 개념을 이용하여 정의할 수 있다.
어떤 스케줄도 serializable 하게 만들 수 있는 개념이 concurrency control 개념이다. 그리고 concurrency control과 관련된 개념이 isolation이다.
isolation은 너무 엄격하면 성능이 떨어진다. 이 isolation을 조금 완화시켜서 개발자들이 유연하게 선택할 수 있도록 한 개념이 isolation level이라 볼 수 있다.
recoverable schedule
위의 4가지 schedule 말고 다른 스케줄을 보자.

위의 그림에서 문제가 발생하는 이유는 transaction 2 가 롤백이 되면서 이다. 트랜잭션2는 롤백이 되면서 트랜잭션 2가 시작되기 전 상태(잔액 200만원)로 돌릴 것이다. 그럼 transaction 1이 실행한 20만원 입금은 사라지게 된다.
transaction2가 유효하지 않게 되었기 때문에 transaction2가 작업했던 잔액을 읽은 트랜잭션1도 rollback이 되어야하는게 맞다. 하지만 transaction1은 이미 커밋이 되었기 때문에 durability 속성때문에 rollback될 수 없다.
📌 unrecoverable schedule
이처럼 schedule 내에서 commit 된 transaction(t1)이 rollback된 transaction(t2)이 write 했던 데이터를 읽은 경우를 unrecoverable schedule 이라고 한다.
즉 유효하지 않은 데이터를 읽게 된 트랜잭션이 있는 schedule 이라고 보면 될 것 같다.
이런 스케줄을 rollback을 해도 이전 상태로 회복 불가능할 수 있기 때문에 DBMS가 허용하면 안된다.
그럼 어떤 스케줄이 recoverable schedule일까?
5번째 케이스의 경우 commit순서를 바꾸면 해결이 된다. 그럼 tx2가 먼저 rollback이 되었다면 tx1도 rollback을 시켜줄 수 있게 된다. 여기서 확인할 점은 이처럼 의존성이 있는 경우 의존되는 트랜잭션(tx2)이 종료가 될 때 까지 의존하는 트랜잭션(tx1)은 먼저 commit 되면 안된다.
이해 참고: tx1은 write한 tx2의 데이터를 읽기 때문에 tx1은 tx2를 의존했다고 볼 수 있다.
📌 recoverable schedule
schedule 내에서 그 어떤 transaction도 자신이 읽은 데이터를 wrtie한 transaction이 머저 commit/rollback하기 전까지는 commit 하지 않는 스케줄을 recoverable schedule이라고 한다.
rollback할 때 이전 상태로 온전히 돌아갈 수 있기 때문에 DBMS는 이런 recoverable schedule만 허용해야 한다.
cascading rollback
tx2가 rollback이 되어서 유효하지 않게된 데이터를 읽은 tx1도 rollback 된 상태를 아래와 같이 정리할 수 있다.
📌 cascading rollback
하나의 transaction(tx2)이 rollback하여 의존성이 있는 다른 transaction(tx1)도 연쇄적으로 rollback 해야하는 상황이라고 볼 수 있는데 이런 상황을 cascading rollback이라고 한다.
cascading rollback은 여러 transaction의 rollback이 연쇄적으로 일어나면 처리하는 비용이 많이 든다.
이를 해결하기 위해서 데이터를 write한 transaction이 commit/rollback 한 뒤에 데이터를 읽는 schedule만 허용하면 된다!
이러면 tx2가 commit/rollback이 된 후 다른 tx1이 데이터를 읽는다면 tx2가 어떻게 했든 tx1은 따로 rollback을 할 필요가 없다.
📌 cascadeless schedule
schedule 내에서 어떤 transaction도 commit되지 않은 transaction들이 write한 데이터는 읽지 않는 경우를 말한다.
(avoid cascading rollback 이라고도 부른다.)
cascadeless schedule도 약간의 문제가 있을 수 있다. 아래에서 살펴보자.
사장이 3만원인 피자 가격을 2만원으로 낮추려고 하고, 직원도 동일한 피자 가격을 실수로 1만원으로 낮추려 했을 때 어떤 schedule이 생길 수 있을까?

일단 두 트랜잭션 모두 읽는 작업이 없어서 cascadeless schedule이 아니라고 볼 수 있다.
그래서 cascadeless schedule에서 읽는 작업만 막을 뿐 아니라 읽는 작업도 막게 보강해 주어야 한다.
strict schedule
📌 strict schedule
schedule내에서 어떤 transaction도 commit 되지 않은 transaction들이 write한 데이터는 쓰지도 읽지도 않는 경우
strict schedule은 rollback할 때 recovery가 쉽다. transaction 이전 상태로 돌려놓기만 하면 된다.
concurrency control
concurrency control은 serializability와 recoverability를 제공한다고 볼 수 있다. 이와 관련된 트랜잭션 속성이 isolation이다.
📌 Conflict serializable
serial schedule과 conflict equivalent인 스케줄
📌 cascadeless schedule
schedule 내에서 어떤 transaction도 commit되지 않은 transaction들이 write한 데이터는 읽지 않는 경우

https://www.youtube.com/watch?v=DwRN24nWbEc
https://www.youtube.com/watch?v=89TZbhmo8zk
쉬운 코드님의 영상을 보고 정리하였습니다.
'knowledge > computer science' 카테고리의 다른 글
| Transaction isolation level (0) | 2024.06.19 |
|---|---|
| [DB] 트랜잭션과 ACID (0) | 2024.06.18 |
| [성능 테스트] Artillery 시나리오, 파라미터 (0) | 2024.06.07 |
| [성능 테스트] Artillery 설치 (0) | 2024.06.06 |
| [성능 테스트] 필요한 배경 지식 (0) | 2024.06.03 |